SEO对倒排索引这个词并不陌生,但倒排索引的原理和索引结构具体是什么?索引的本质是在解决什么问题?为什么要用倒排索引?这一系列问题你会在阅读完本篇文章后有比较清楚的答案。
索引是什么?


如脑图所示,索引的存在便是为了解决将互联网海量信息进行分类,以一种合理的方式形成索引结构,让用户快速找到有价值的信息,索引结构在我们生活中也非常常见,比如一本书的目录、浏览器的导航页面等等。
什么是正向索引?
当用户搜索某个关键词时,扫描索引库中包含该关键词的所有文档,再根据综合算法打分进行排序最终展现,这就是——正向索引,通过文档找词。
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

什么是倒排索引?
由于正向索引无法满足互联网海量的信息实时返回排名结果需求,所以便将正向索引的内容重新排序,把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件这便是——倒排索引,通过词找文档。形成倒排索引表之后以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。
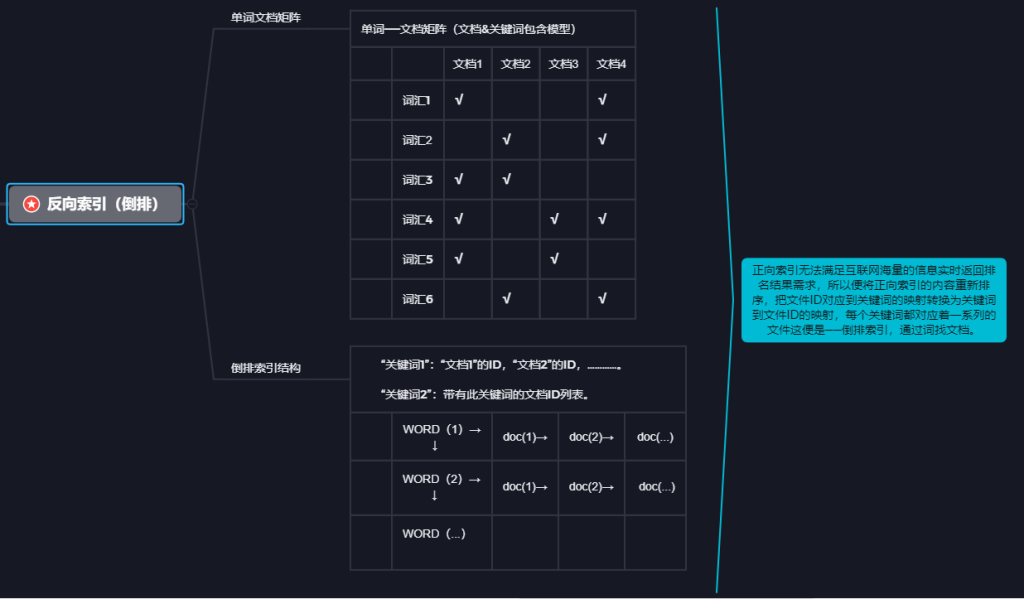
上述脑图简单将倒排索引的单词文档矩阵和结构进行了举例展示,可以看到倒排索引结构上与正向索引相反,其实用性更强,充分解决了正向索引存在的短板问题,我们来详细来代入实际案例中看下面的案例图:

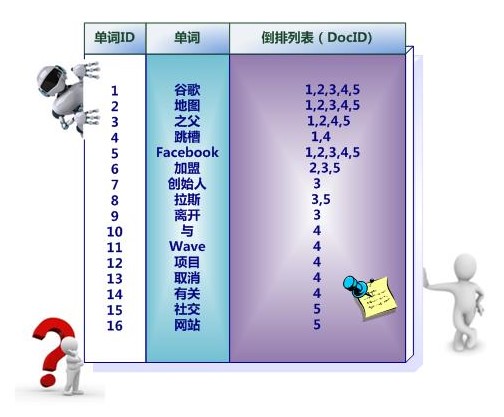
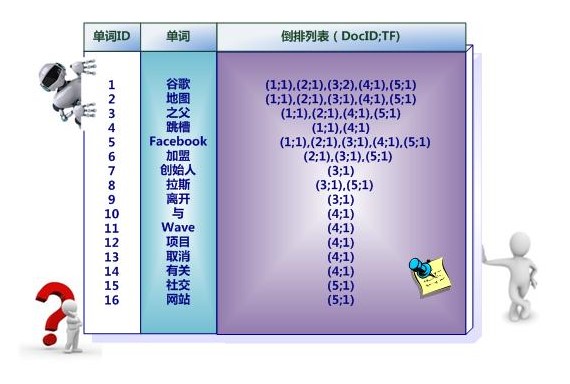
单词ID:记录每个单词的单词编号;
单词:对应的单词;
文档频率:代表文档集合中有多少个文档包含某个单词
倒排列表:包含单词ID及其他必要信息
DocId:单词出现的文档id
TF:单词在某个文档中出现的次数
POS:单词在文档中出现的位置
倒排索引基本概念(摘自《这就是搜索引擎》)
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。
文档集合(Document Collection):由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
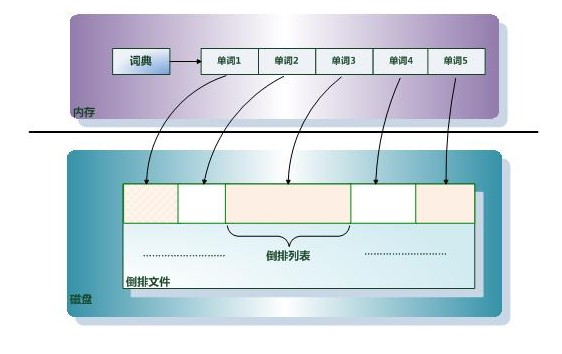
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
完整脑图
发布者:超威蓝猫,转转请注明出处:https://seowki.com/seo/baiduseo/4118.html
评论列表(1条)
[…] IDFk=log(N/nk)文档中的的N代表文档合集中总共有多少个文档,nk则代表特征单词K在其中多少篇文档出现过,也就是我们通常说的文档频率。从公式中我们能看出nk值越大,IDF值就越小,IDF值代表了单词带有的信息量有多少,IDF值得高低代表信息越有价值,可以把他通俗的理解成:物以稀为贵。总结:对SEO而言,我们可以思考一个问题,文档集(不清楚文档集概念的可以查看下:什么是倒排索引,正向索引和倒排索引的区别是什么?)我们不可控制,那我们能否从拓词的时候选好要做的核心词,从而达成控制IDF所得的权值? […]